

The next school year is about to start, and my wife (a high-school Spanish teacher) had an idea for her class. So, let me introduce you to our latest creation: Teacher Assistant Frida. An animated character who will listen and answer basic questions in Spanish.

It was built using vanilla JavaScript and an inline SVG. Unfortunately, for now it only works in specific browsers because it uses two experimental Web APIs (Speech Synthesis and Speech Recognition) that are not widely supported yet.
It is still a work in progress and needs polishing, but it looks promising for what we want. After all, it was developed quickly in an afternoon —including the SVG— and it's less than 250 lines of code among HTML, JS, and CSS.
Before we continue, this is a demo of Frida (to see a running demo, go to the bottom of this article):
Why in JavaScript? Why Frida?
Having a virtual assistant that analyzes speech and replies accordingly sounds like something that would require more than just vanilla JavaScript. And even when possible, there probably are better alternatives for building such a thing... but we had some limitations.
The assistant was for a high school, and the school IT department has restrictions:
- We cannot install any software. Therefore, building an app was not an option, which considerably limited the technologies we could use.
- We cannot access certain websites, as the school firewall blocks many of them (and the list is kind of ridiculous in some cases.)
- We cannot import content into websites (something that is related to the previous point.)
We had plugged vanilla JavaScript into the school web tools on previous occasions, so it seemed like a good option. Also, it would reduce the learning curve to just the Web Speech API.
We didn't expect much. After all, we wanted something simple, but I have to admit that the results were a lot better than what we expected.
And why Frida Kahlo? The assistant is for a Spanish class, and we wanted a recognizable character associated with the Spanish language and culture. A cartoon of Frida Kahlo matched that perfectly... and it was simple to draw.
As you may have noticed, there's a pattern in most of our decisions. Most of them were based on answering, "What is the simplest option for this?" There was no real reason to overcomplicate things initially (that would come later, anyway.)
Speech Recognition API
The Speech Recognition API is big, and this is not going to be a deep dive. We are only going to review the code associated with our virtual assistant. Visit the MDN site for more information about the API.
This is a simplified version of the speech recognition code:
// new speech recognition object in Spanish!
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.lang = "es";
recognition.onstart = function () {
// actions to be performed when speech recognition starts
};
recognition.onspeechend = function () {
// stop speech recognition when the person stops talking
recognition.stop();
}
recognition.onresult = function (event) {
// get the results of the speech recognition
const transcript = event.results[0][0].transcript.toLowerCase();
const confidence = event.results[0][0].confidence;
// perform actions based on transcript and level of confidence
}
For security reasons, the speech recognition code can only be executed after the user triggers an event. It makes sense. We wouldn't want to have a website listening to the users without them realizing (although they'll be asked to provide access to the microphone.)
To go around this, we added a button that occupies the whole screen, and that starts the speech recognition when clicked:
recognition.start();
This allows the teacher to walk around the classroom and click the button with a mouse or a pointer. Then they can simulate a conversation with the assistant or ask the students to ask for something.
Also, we can use the Speech Recognition events to animate the assistant and do something while it listens. For example, Frida raises an eyebrow (which may be a mistake as it makes her look like she is over with the conversation.)
Now, let's talk compatibility and support. The Speech Recognition API is supported by Chromium and the latest version of Safari, but not by Firefox or most mobile browsers:
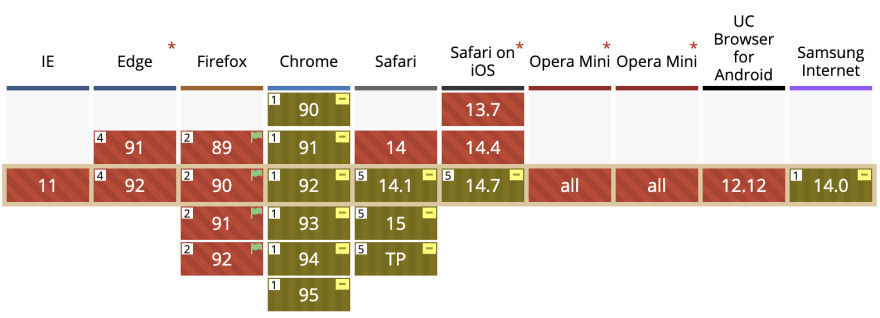
As the user (the teacher) has, and will specifically use, a browser that supports the feature (Chrome), this is not a problem for us.
Speech Synthesis API
As with the Speech Recognition API, this will not be a deep dive but a demonstration of how the assistant uses the API.
The next for our assistant was answering the questions from the teacher and students. Of course, we could record all the answers and play them at the right time, but that would be time-consuming and a little bit of a pain... and remember, we were always looking for a simple option.
The simplest solution was using the Speech Synthesis API: why record sentences and more sentences every time we wanted to handle a new feature? Wouldn't it be better if the computer could read whatever phrases we provided?
And the code was more straightforward than we expected. Four lines of code had our assistance saying some sentences:
let speech = new SpeechSynthesisUtterance();
speech.lang = "es";
speech.text = "This is the text to read.";
window.speechSynthesis.speak(speech);
Similar to the Speech Recognition API, we need to wait for user interactions before using the Speech Synthesis API. Luckily for us, we can piggyback both actions with the same event: once the button is clicked, the assistant will listen and process the speech; and once the speech is processed and converted into text, we can make the assistant speak.
The Speech Synthesis API is more complex than just those four lines of code. It allows for complete customization of the speech: speed, pitch, even the voice can be selected from a list of available ones.
In our case, the default speed is good. It may be a bit slow for a native speaker, but it's okay for students. Our main concern was the voice in itself. Frida is female, but the default voice depends on many factors (browser, language), and in some cases, it may be a male voice. But we can select it specifying the voice property.
Let's talk about support. While still experimental, the Speech Synthesis API is widely supported (it works in 95% of the active browsers!), so this was not a problem at all:
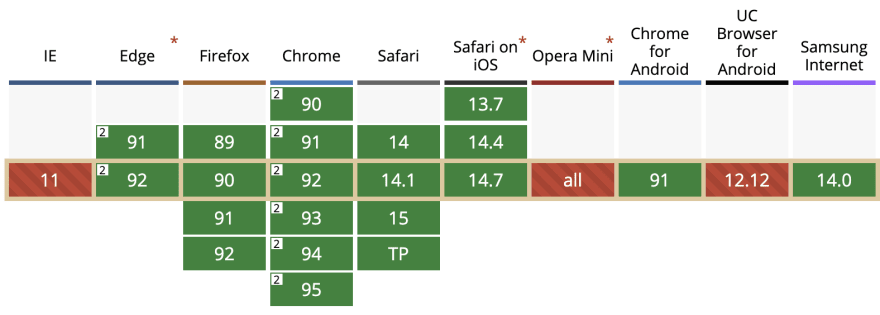
We can use (and we did) the Speech Synthesizer events to add more animations to the assistant. For example, making her lips move while the computer is reading the text... although it was a bit of a pain because the timing is not 100% accurate, we needed to make it match with the CSS animation to avoid weird jumps. Not ideal, but still doable.
It's not AI! Just a ton of conditionals
There's a joke online about AI and if statements:
And that's precisely what our assistant is. We are not going to pretend it is Artificial Intelligence. It is not really AI, but a bunch of chained conditionals (not even nested.)
Once we get the results from the speech recognition, we have two values: the text from the speech and the confidence that the system has in the recognition. We noticed that the result is generally good when the confidence is higher than 75%.
If that's the case, then we check for substrings within the transcript:
- What time is it?
- What's the forecast for today?
- What is today's date?
- What day of the week is today?
- Who is the best teacher?
And match them with auto-generated answers using other JavaScript APIs or predefined sentences:
// default text
let textToSpeak = "Sorry, I didn't understand.";
if (confidence > 0.75) {
if (transcript.indexOf("time") > -1) {
const d = new Date();
const hours = d.getHours();
let minutes = d.getMinutes();
if (minutes === 0) minutes = "o'clock";
textToSpeak = `It is ${hours} ${minutes}`;
} else if (transcript.indexOf("best teacher") > -1) {
textToSpeak = "Miss Montoro is the best teacher";
} else if...
}
// Speech Synthesis code goes here
The Speech Recognition API allows for the use of grammars that could be useful to classify the results. While we don't use them now (an if statement seemed simpler at the time), it may be an exciting enhancement for a second version.
Working Demo. What's next?
Here's a demo of Teacher Assistant Frida:
Note: the demo may not work while embedded because of the
iframesecurity policy. Click on the link above or on Edit on CodePen to see it working.
As a minimum viable product, this class assistant is fine, but it is far from complete. Here are some of the things that we think about improving:
- Add more sentences and questions to understand
- Add grammar to the speech recognition system so that we can simplify the code (and remove the ugly conditionals)
- Add customization/settings so that other teachers can use it after a minor update.
- Expand with new features using other Web APIs. Some ideas that we have:
- Detect the ambient noise, and if it reaches a threshold, make Frida look angry and say, "Silence, please!"
- Dress Frida differently depending on the date and weather.
- Make Frida a little bit friendlier (she always looks angry in the cartoon.)
- Add a list with student names so that Frida can call them randomly for questions/tests.