Web pages can be confusing at times: poorly structured, disorganized, with many errors and mistakes... But that's not what this article is about (at least not completely). This is about websites being confused and disoriented.
So, how can something that doesn't have a mind of its own like a website be confused? What are the causes of this illness in web development?
It's all about the metadata.
It can happen when the pages don't have metadata to describe its content. Or when the pages on a site have or share incorrect metadata (something that could happen when using poorly designed templates or routing).
And the consequences of this seemingly innocent problem can be devastating:
- Poor search engine placement: appearing low in searches, or even worse in the second page of Google results.
- Poor control over social sharing: developers do not decide what or how the content is displayed.
- Poor social distribution: which in a world dominated by social networks is a huge issue.
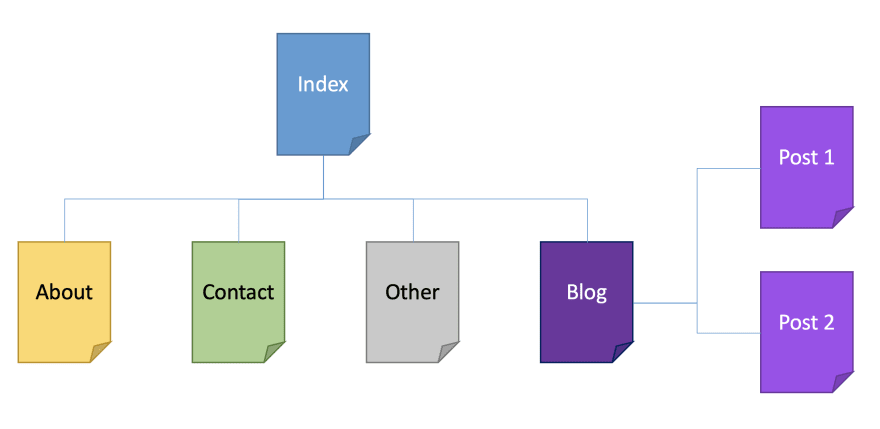
But let's see it better with an example. Imagine the following site structure, really common among personal sites and blogs:
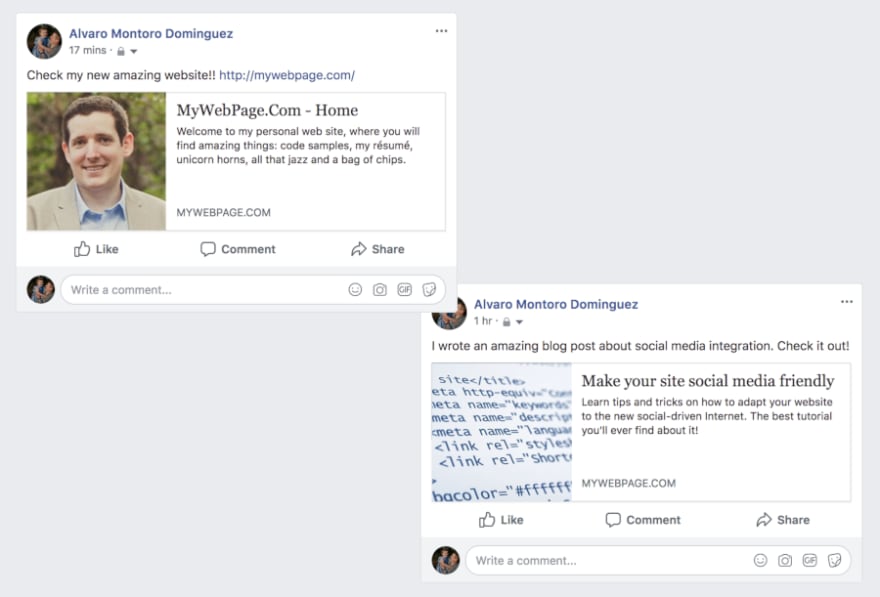
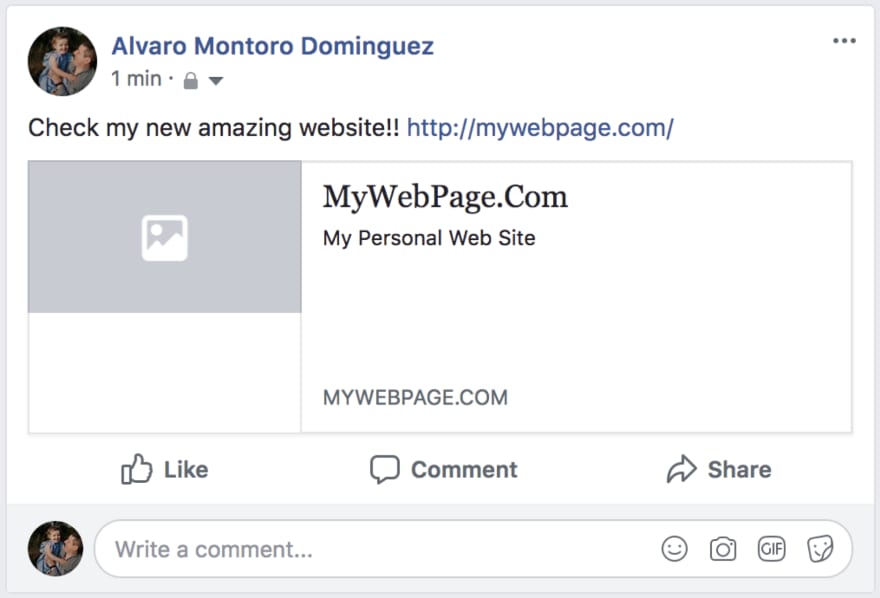
You are proud of the new site that you develop and decide to share it on Facebook, but you don't have any metadata. Chances are, the card on your post will look like this:
Now you write a blog post, and decide to share it on Facebook too:
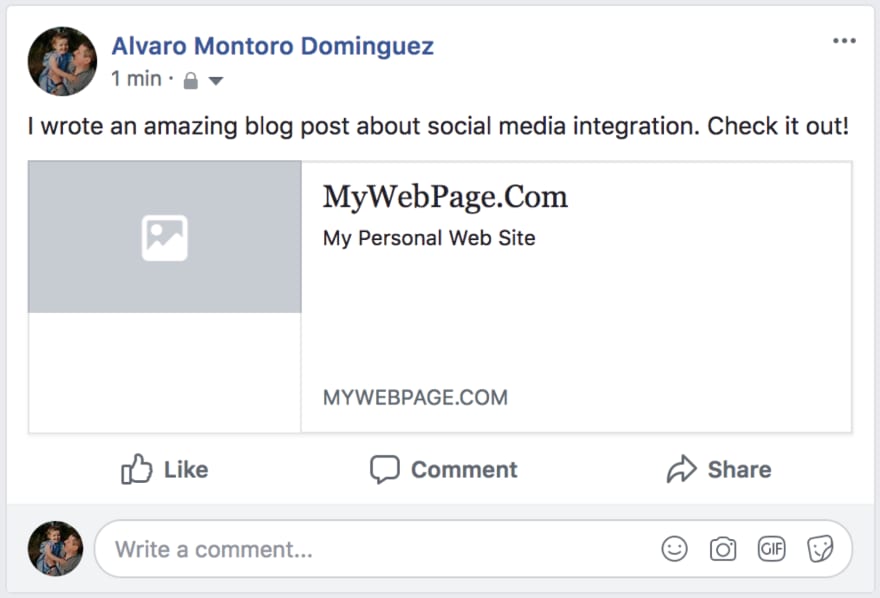
There's a pattern here. Even when the developer may think that all the pages are unique and different. For social media sites and search engines, it looks more like this:
I know this is a bit of an exaggeration, but it is to better illustrate the issue, and point to where the web confusion happens: the index page is shared as the index, the blog is shared as the index too, and so are the blog posts or the contact page... all of them think that they are the index page!
This creates confusion among the users that see them shared in social media, and memory problems on search engines, that are unable to differentiate the pages and rank them lower.
So know that we have seen the web illness and the bad consequences that it carries, the next question is...
How to cure Web Confusion?
Web confusion can be solved in 4 steps. The first two are so basic, that any site should fulfill them without problems because they don't really need any special changes, they are (or should be) completed just by following some common sense... yet, many sites and pages don't even comply with them.
1. Have well structured and significant content
Crawlers will analyze the content of your page and try to index/display it on the best possible way based on its content.
So even if you don't do any of the following 3 steps, try to have good quality content and well structured segments (don't forget the HTML headings!)
Your pages will be crawled and indexed, and they may show up high in the search results, and social media sites will display them "correctly"... but developers didn't have a say on what the displayed content was.
2. Use standard HTML meta tags
A meta tag is a tag that offers information about the information contained on the page: title, description, author... They go in the <head> and are hidden to the user while visible for the machines and bots:
<head>
<title>Title to Display</title>
<meta author="Alvaro Montoro">
<meta name="keywords" content="relevant,keywords,describing,page">
<meta name="description" content="Description of page content">
...
In the past, it was the main source that search engines used in order to index the web pages. But now it's not that important as search engines are smart enough to process everything on your site: content, links, images, etc. Still, it's a nice to have thing.
3. Use OpenGraph and social media tags
The Open Graph protocol enables any web page to become a rich object in a social graph. It includes information similar to the meta tags, and then takes it to the next level.
Not only it is used to specify things like the title or a description, but it also goes deeper: type of document, images, sounds, and videos that represent it... allowing the sites that crawl and use your page to display the data, personalized and rich information.
<meta property="og:type" content="website">
<meta property="og:title" content="Page Title">
<meta property="og:description" content="Description of the page.">
<meta property="og:url" content="link.to.be.displayed.when.shared">
<meta property="og:image" content="link.to.thumbnail.image">
<meta name="twitter:card" content="summary">
<meta name="twitter:title" content="Page Title">
<meta name="twitter:description" content="Description of the page.">
<meta name="twitter:url" content="link.to.be.displayed.when.shared">
<meta name="twitter:image" content="link.to.thumbnail.image">
Open Graph is used by Facebook, Skype, Google+, LinkedIn... and even Twitter (that has its own meta tags too.)
4. Use Microdata
Microdata on the other hand is a different concept, and it would be more like the cherry on top.
The metadata goes directly in the content providing search engines, web crawlers, and browsers a better understanding of what the content is. That is because what we are doing is associating tags and content with elements from a pre-existing schema. And that way, the meaning of the content is not only understandable for the person but also for the machines.
<div itemscope itemtype="http://schema.org/Movie">
<h1 itemprop="name">Avatar</h1>
<span>Director: <span itemprop="director">James Cameron</span></span>
<span itemprop="genre">Science fiction</span>
<a href="../trailer.html" itemprop="trailer">Trailer</a>
</div>
After all these changes, the content of the web pages is unique and it is shared in a unique way with bots, search crawlers, and social media sites.
Developers regain control over the content and how it is displayed online, and the results are more appealing and visible almost immediately: